Mastering Large-Scale Web Scraping: Strategies, Solutions, and Ethical Guidelines
 0 Minutes Read
0 Minutes ReadFor modern businesses like yours, data-driven excellence has become more crucial than ever.
Gathering bulk amounts of fresh, reliable data from several online sources and turning it into actionable intelligence is the fool-proof way to scale your business.

But how do you plan to scrape the endless internet, brimming with countless web pages and oceans of data? Manually, racing your fingers through every big and small website? This would take centuries.
Perfect solution you ask? Large-scale web scraping it is.
Web scraping techniques have evolved — famously, large-scale web data scraping — in scope and size to overcome anti-scraping measures and security protocols.
However, large-scale data scraping is complicated and may pose challenges such as setting up infrastructure, managing costs, legal constraints, and establishing anti-bot detection systems.
You should understand the tools, tricks, and ethical considerations to ace the data scraping game at scale.
Read on to learn everything about becoming a large-scale web scraping pro — efficiently and ethically.
With web scraping, professionals now have a steady flow of updated information right at their fingertips.
What is large-scale web scraping?
Given the immense volume of data generated by users worldwide online, retrieving this information demands significant time and resources. Relying solely on manual methods proves impractical. These operational and financial challenges call for large-scale web scraping.
Large-scale web scraping is a continuous process that automates data extraction from millions of web pages simultaneously using crawlers instead of manual collection. This enables the extraction of large amounts of data from the World Wide Web.
There are two types of large-scale web scraping:
- Pulling data from high-traffic websites like Amazon and LinkedIn
- Scraping information from hundreds of thousands of small websites
Both methods can be successful given the tools for data gathering and extraction, driving informed decision-making, and facilitating product development.
Below are key elements of large-scale web scraping:
- Data Extraction is retrieving data from websites using automated scraping tools or programming libraries.
- Data Parsing is structuring and cleaning the extracted data for easy analysis.
- Data Storage involves storing scraped data in databases or file systems for deeper processing.
- Data Analysis uses statistical techniques and machine learning patterns to generate insights from the pulled data.
How can you benefit from large-scale web data scraping?
Stakeholders depend on data scraping to optimize business strategy, track competitors, improve decision-making, manage risks, and train AI models to analyze customer habits. All to stay on top.
Large-scale web scraping, when conducted responsibly and ethically, can offer several convincing benefits:
Competitive intelligence for beating your competitors
Scraping data from competitors' websites helps you gain valuable insights into their strategies, pricing, product offerings, and market positioning. This information enables proactive decision-making around your products and services.
Improved SEO for targeted messaging
Data mining and extraction are powerful catalysts in your SEO journey, empowering you to gather pertinent data on keywords and search trends. This, in turn, facilitates more effective messaging and communication targeting the right audience with precision.
Know the risks before they occur
Actively detect security threats like phishing scams and malware early on, saving costs and minimizing risks. Besides, monitoring news and social media sources helps you stay informed about potential market disruptions, reputational issues, and regulatory changes, enabling quicker risk mitigation and impact cancelation.
In-depth market research for smarter personalization
Extracting valuable insights such as user reviews and social media activity allows businesses to understand customer preferences, fostering individual-level personalization and product/ service customization to meet user needs.
These insights enrich existing data allowing you to paint a more detailed and accurate picture of your customers' experiences and adapt to earn their loyalty.
Data acquisition for fool-proof market position
Efficiently collecting innumerable amounts of data from 1000s of internet sources facilitates easy market research, trend analysis, sentiment analysis, and more.
Price monitoring for improved sales and revenue
Large-scale scraping is a big deal for e-commerce platforms to monitor product prices and services across marketplaces. E-commerce business owners can adjust their pricing strategies in real time after analyzing market dynamics, competitor pricing, and consumer demand.
Automation to fast-track processes and productivity
With automated data scraping, businesses can save valuable time and resources. Protected resources and time availability empower teams to focus on more value-added tasks and produce value.
Lead generation and higher conversions
Scraping data from public directories, social media platforms, and other online sources can help businesses generate leads for sales and marketing purposes. Focused data collection allows targeted campaigns and promotions to contact potential users.
Enhanced decision-making
Large-scale scraping provides a wealth of data to businesses to identify patterns, trends, behaviors, and correlations. Deeper analysis enables data-driven decisions across various functions such as marketing, product development, and operations, leading to more educated and effective strategies.
Innovation and research for better solutions
Researchers and developers can access large-scale data to produce invaluable innovation and knowledge. This data helps in training machine learning models, developing new algorithms, conducting academic research, and driving innovation in various fields.
Let’s understand examples of large-scale scraping
Suppose you're interested in gathering data from a popular news website to analyze articles in a specific category. This category spans 10,000 pages, with each page containing 30 articles. That's a whopping 300,000 articles to crawl and scrape.
If each page takes around 3 seconds to load, calculate the loading time for 10,000 pages manually. Roughly, the time to load all the pages is 900,000 seconds or 10+ days.
Attempting to extract data from each article manually would take even longer. Manual data extraction is excessively time-consuming and inconvenient to retrieve such a vast amount of data by hand.



Moreover, running the scraping process in parallel allows data extraction from multiple web pages per second.
As a result, a large-scale scraping system enables you to achieve intelligent results in a time fraction without manual intervention.
Now, let’s explore what you’ll need to perform web scraping at a large scale.
What are the steps to perform large-scale web scraping?
For starters, clearly define the data you require and the reasons behind it. This understanding will shape the entire scraping process. Performing manual data extraction is too time-consuming to be practical. Choose automation for tangible results.
Next, you'll need a stable scanning system capable of scraping millions of web pages for rapid data extraction. Besides, your automated scraping tool must effectively sidestep anti-scraping measures and handle dynamic content. We'll talk about these challenges later.
Building and managing your web scraping infrastructure is the first step. The web scraping pipeline generally looks like this:

Now, let's dive into what you need to do and understand to set up a large-scale web scraping process:
1. Establish a continuous scraping process
Start with developing a data collection method (a crawler + scraper) that will serve as the backbone of your scraping infrastructure.
Building a crawling path requires a list of URLs to scrape data from. For smooth scraping, create a continuous process that can handle multiple pages simultaneously.
Both crawling and scraping must work in tandem for optimal results.
Using numerous small scrapers is better than a huge spider crawling multiple pages. Designing a small scraper for each page type allows for parallel scraping, extracting data from various sections.
Each scraper can work on several pages in the backend, achieving a dual level of parallelism.
Preventing duplicate crawling of pages requires an orchestration system that saves time and resources. One way to achieve this is by storing crawled page URLs and timestamps in a database. The storing method enables the system to filter crawled pages, ensuring efficient resource use.
Lastly, to ensure system continuity, crawl all relevant pages and scrape them simultaneously.
2. Choose premium-level web proxies
Using high-yield proxies helps your scrapers from getting blocked by websites when conducting large-scale web scraping.
Websites track requests from IP addresses and analyze them for security. Too many requests from the same IP get the address blocked. Proxies camouflage your location by changing your IP after each request to ensure continuous scraping.

Premium proxies should provide features such as rotating IPs, ensuring your scraper remains anonymous and untraceable each time you perform a request, and reducing the risk of getting blocked.
What is the wisest proxy choice? Residential proxies. They offer a wide range of locations and a large pool of IP addresses that don’t get you blocked as compared to data center proxies.
It's crucial to choose a reliable proxy provider. Unreliable proxies can cause your scraping tool to perform poorly, affecting your data retrieval process on the go.
3. Advanced Data Storage Systems
When conducting large-scale web scraping, massive amounts of data are retrieved. But where should all this data go? While spreadsheets may suffice for small-scale scraping and processing, extensive procedures require more robust options like MySQL or cloud storage services.
Storing data is an art.
Let’s understand data that needs storing. When scraping, you generate two types of data: raw and processed.
Raw data is the HTML pages your spiders crawl. Storing it in unlimited cloud storage is efficient but costly.
Processed data is a refined version of the raw data. Your scraper pulls this data from the HTML and stores it in database rows in human-readable formats. Relational or NoSQL databases are better choices for easy data streaming and access whenever needed.
Data sorting from large-scale scraping demands substantial storage resources.
Imagine you're running a price comparison across various e-commerce sites. Now, let's crunch some numbers:
If you're scraping prices from 10,000 products per second, and each product page contains an average of 50 price points, you're dealing with a hefty amount of data flow.
Assuming each price point takes up around 1KB of data, you'll be processing 500KB of data per second. When compressed, this amounts to 1.5GB per hour of scraping.
Now, let's extrapolate that over a more realistic timeframe:
24 hours of scraping = ~36TB of data
1 month of scraping = ~1.1PB of data
With such a colossal data influx, the importance of efficient storage solutions becomes obvious.
Now, the question arises: What will you do with all this data? Why store the data? Will you process it into readable formats like JSON or retain raw HTML files alongside processed data?
Before answering these questions, let’s decide where to send this data.
Direct transmission to a service provider or parser is an option, but using a buffer could help more. Buffers help manage the disparity between data receiving and processing rates.
4. Creating a buffer for data transfer
Let's simplify buffering with a simple library example. Imagine you’re at the library to return the books. The librarian places the books on a cart—a buffer. This cart has limited space, like shelves. Stacking up too many books will fall off the cart causing a ruckus.
To avoid this, the librarian sets the maximum number of books the cart can hold. Once it's full, new books must wait until there's space. If the cart overflows, the librarian has to either remove some books or pause accepting returns until they can catch up.
Now, in your case, if you're waiting for another service to take the information, you'll need a buffer to keep track of the transferred data. You aim to prevent overflow, just like with the book cart.

However, if you pause your scraping process, you'll have more work to catch up on later.
So, what do you do with all the data you've scraped? Let's find out.
Database storage and processing
Imagine you want to process incoming data into a readable format, like JSON, CSV, XML, AVRO, Protocol Buffers, Parquet, or ORC. You can store raw data in short-term storage. But what if you want to keep the HTML files with the processed data? Long-term storage is the way to go.
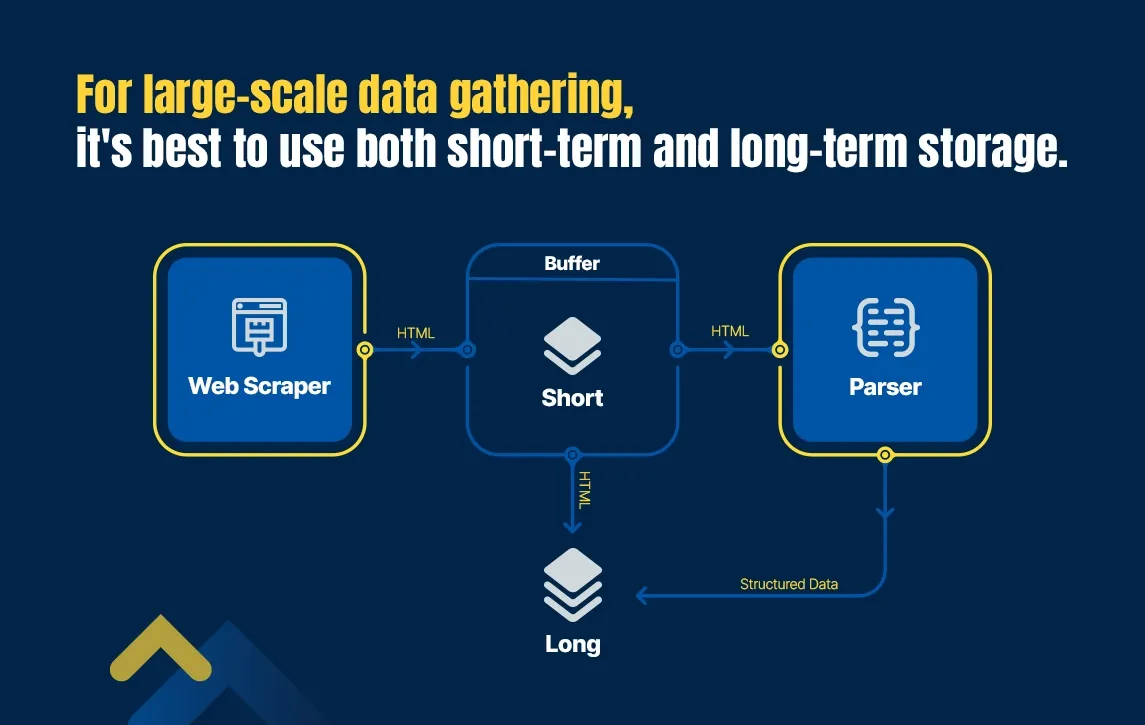
Here's why:
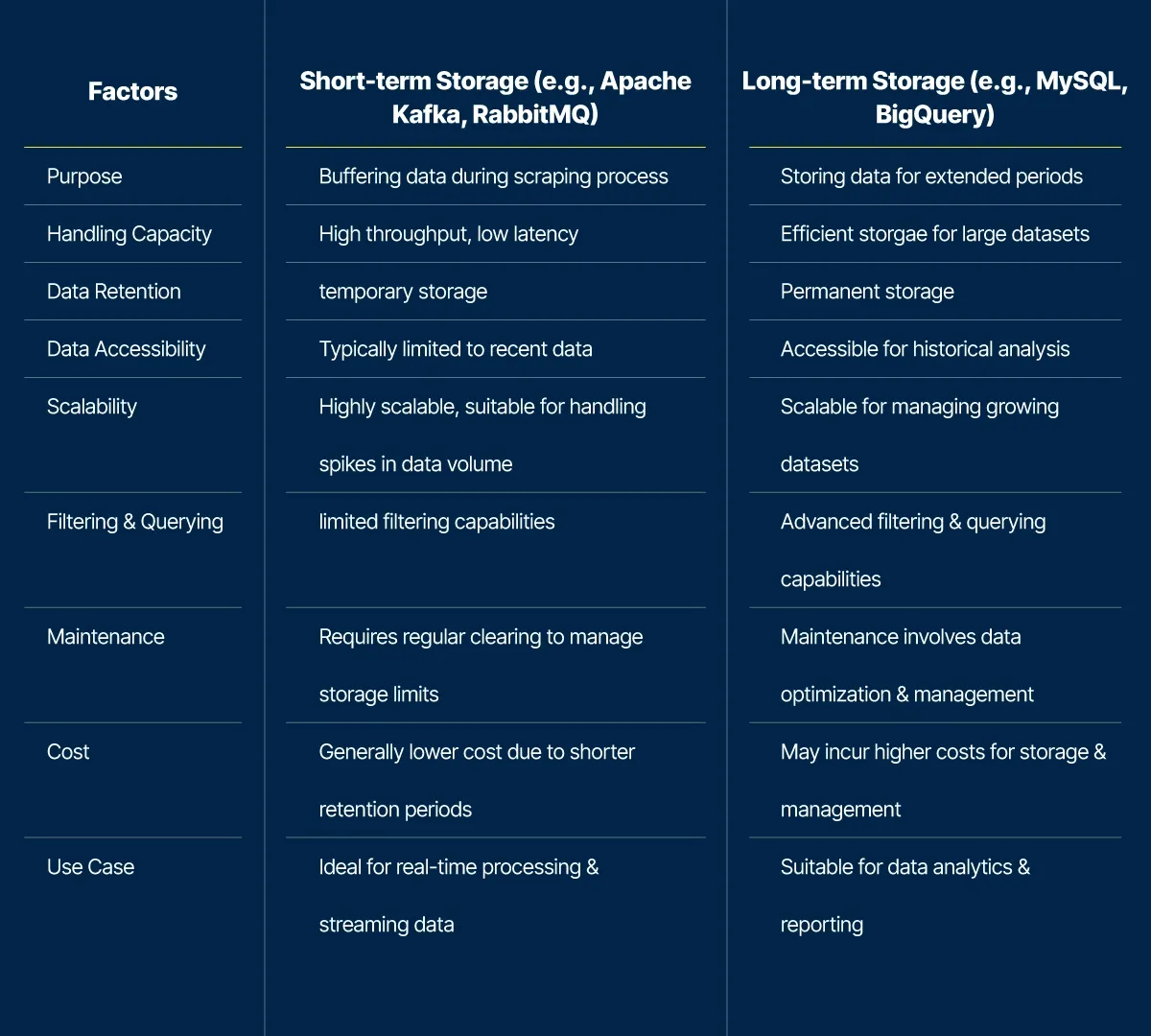
Short-term storage databases like Apache Kafka or RabbitMQ are high-end options to handle high volumes of requests to achieve high throughput and low latency levels. It acts as a buffer for absorbing data from the scraper, sending it to the parser, and storing raw HTML files.
Long-term storage options include MySQL or BigQuery for keeping data on hard drives. They offer tools for filtering data and are ideal for storing information for a long time.
You can otherwise skip the storage process with state-of-the-art crawlers like Scrapy and Puppeteer, specialized in wide-level data retrieval, delivering the desired data in HTML, XML, JSON, or other suitable formats.
Processing scraped data
You begin processing or parsing the data after planning a suitable storage solution. Data parsing involves studying incoming information and converting relevant pieces into a readable format for further analysis. It's a vital component of the web scraping process.
Once you've stored your data, it's time to feed it into a parser. Typically, when you scrape data, it's in raw HTML format. The parser converts the raw HTML into a more structured and readable format. This structured data enables convenient data analysis and insight generation.
However, performing parsing at a large scale is complex. Building and maintaining a parser for small-scale projects is comparatively simple.
Yes, large-scale data scraping is challenging.
Large-scale web scraping indeed works like a charm. However, it is a tricky process due to technical and ethical challenges. Besides, dealing with oceans of data is difficult. But knowing how to overcome these difficulties is your true success.
Every webpage you scrape has anti-bot bot systems installed that detect and block unwanted bots. Unfortunately, even the good bots are mistaken for malicious ones and get flagged.
Websites maintain various anti-scraping measures, such as:
IP Recognition
This one’s a common problem. Servers can detect whether the IP is from a data center or residential source. Datacenter proxies are often blocked as they aren't associated with human users like residential proxies.
CAPTCHA
Another popular anti-bot measure is a challenge-response test that asks users to input correct codes or identify objects in pictures. Bots struggle to pass CAPTCHAs and are easily recognized and blocked.
Cookies
Typically, users land on a specific product page via indirect sources such as search engines or ads. In such cases, mimicking real user behavior helps obtain cookies without getting caught.
Browser fingerprinting
Websites gather device-specific information for identification, including operating systems, languages, plugins, hardware, and fonts. Bots replicate organic user data to avoid detection.
Headers
Websites typically analyze geolocation, time zone, language, etc. Inconsistent or incoherent data combinations can, therefore, trigger blocking.
Behavioral inconsistencies
Illogical mouse movements, rapid clicks, repetitive patterns, average page time, requests per page, and browsing starting points without collecting HTTP cookies can get your bots noticed and blocked.
Tips for building a fool-proof large-scale scraping system
Choose a suitable web scraping framework
Select an open-source framework that offers adaptation and customization before starting your web scraping project. Closed frameworks can restrict control and pose risks if you don’t use them.
Prepare for anti-bot detection
Websites implement anti-bot measures to catch and block bots, including CAPTCHAs, IP blocking, and other behavioral anomalies.
You can however bypass anti-bot systems like Cloudflare and Akamai by staying mindful and updated on anti-bot protection systems and adjusting strategies accordingly.
Unknown challenges arise as your scraping expands that may deter your anti-bot detection systems.
Keep your web scrapers fresh
Websites constantly evolve against data privacy threats. You should regularly update your scrapers to adapt to changes. Otherwise, prepare yourself for tons of scraping errors or poor-quality data extraction.
Scale-up performance
Leverage headless browsers for faster scraping, but stay vigilant that they also take time to load pages fully, impacting performance.
Test and track your data quality
Test your freshly scraped datasets for quality, accuracy, and relevance routinely. Set benchmarks for quality information and automate the verification process for large-scale operations.
Be mindful of storage solutions
Always consider your data-gathering scope before scraping to predefine suitable storage strategies.
Large-scale operations make hundreds or thousands of requests per second and require a robust storage solution. Start with spreadsheets and transition to databases like NoSQL for seamless distributed data management.
Know your limits
Know your expertise and resources as well as their limitations. Start with smaller projects and scale up gradually to avoid burnout and maintain data quality.
Adapt to varying website structures
Websites differ in design, layout, and coding, which changes over time. Stay relevant by regularly updating your large-scale web scraper according to each website's unique structure. You can rely on custom-made scraping programs for various sites to optimize performance.
But is large-scale web scraping legal?
Some people can simply term web scraping as stealing. After all, how can you pull someone else’s data without their consent?
Thankfully, web scraping is not an illegal practice. When a website’s content or data is published, it is free to scrape.
For example, any product available in the market is legal to scrape. Many business apps and browser extensions use web scraping for product price comparisons.
Nevertheless, not all web data is for public use and is illegal to scrape. Scraping personal data and intellectual property, breaching privacy codes, and playing with a website’s resources are termed malicious and unethical web scraping. Committing these activities results in fines and penalties, notices, and reputation damage.
How can you ensure ethical web data scraping?
These are the ways to stay vigilant about legal and ethical data scraping at a large scale:
Protect sensitive data from unauthorized access.
Process and store sensitive data — such as contact details, payment information, and other personal identification info — with care when scraping multiple web pages. Responsibly implement vital security measures to protect this data from unauthorized access.
Respect website rules and regulations
Adhere to websites' terms of use and policies regarding data scraping. Some websites explicitly prohibit scraping. Thus, you should ethically avoid violating their regulations to avoid legal matters.
Avoid overloading servers
Relentless large-scale scraping can strain a website's servers and disrupt its functioning. Avoid excessive scraping to prevent server overload from affecting the site’s user experience.
Stay cautious of intellectual property rights
Violating copyright or intellectual property rights during large-scale data scraping is a no-brainer. Obtain permission from data owners before using their data to avoid legal consequences, upholding ethical standards.
Consider these legal and ethical considerations when web scraping at scale:

You can scrape data for these legal use cases
News & Social Media Sites
Ensure timely data delivery across news channels and social media platforms with our automated data extraction specialists.
Price, Product, & Reviews
You can actively monitor competitor prices, reviews, and brand reputation across online marketplaces, food stores, pharmacies, apparel stores, etc., and make efficient decisions.
Market Research and Analysis
Boost your marketing campaigns by extracting data from your ideal customer profiles across Facebook, Instagram, TikTok, YouTube, Google Maps, and more.
Stock, Inventory, and Order Management
Keep track of SKU, stock status, orders, prices, and sales from an insights dashboard and ensure seamless inventory management with our industry-wide data scraping services.
Dropshipping Automation
Obtain accurate information from Amazon, Walmart, AliExpress, eBay, Etsy, etc., and get data in preferred formats by hiring our talented web scrapers.
Real Estate and Housing
Fetch real estate listings of properties, agents, brokers, mortgages, construction law permits, foreclosures, and MLS without manually collecting data from multiple sources.
Stock and Financial Market
Keep an eye on global financial markets, stock markets, commodity trading, and economic indicators and boost existing data feeds to redefine internal financial models.
Job Data and Human Capital
Hunt the finest talent, aggregate jobs from job boards or corporate platforms, and keep a record of who your competition is employing with our robust data harvesting services.
Travel, Hotel, and Airline
Analyze travel websites, hotel reviews, pricing, room availability, and airline ticket prices by leveraging our web scraping services and solutions and staying ahead.
Research and Journalism
Feature mind-bending stats and data in your next research project or news story with our best-in-class web service providers offering niche-specific expertise.
So, tell us, what’s stopping you from going data-driven?
- Are you still getting blocked by websites with anti-scraping measures?
- Do you have high-volume data needs?
- Vendor discontinued their service and now you’re unable to fetch data?
- Spending days on data scraping but not getting results?
- Can’t determine the right technology to scrape data?
- Are culture constraints the biggest obstacle to becoming a data-driven org.?
There are ethical and legal considerations when performing web scraping. As a responsible provider of web scraping services, Qbatch ensures ethical and legal guidelines to help businesses gather data responsibly and legally.


Subscribe
Get the top stories like these delivered to your inbox!

You might also like…

Is 2024 The Year of Software Development Crisis?
 0 Minutes Read
0 Minutes Read
5 Truths Behind the Software Developer Shortage 2024: Whom to Blame?
0 Minutes Read